How 4DS can potentially add value to AI
One of the biggest challenges to AI chip developers is a consequence of the massive amounts of data that it processes. Traditional Intel architecture CPUs can’t handle this because so much data must be read into the chip, processed, and the results written back out of the chip. When you are working with so much data that needs to be accessed so fast the bottleneck is in the reading and writing and not in the processing.
As a result, new architectures bring the memory in with the compute [so called Compute in Memory] and are the basis for most AI specific processors today. This has helped a lot but is still limited by the type of memory they can use that can be fast enough for their needs. Today this is predominantly SRAM but there are limits to the amount of SRAM that can be brought into a processor and the sizes of the most advanced AI models are orders of magnitude higher than what can be integrated.
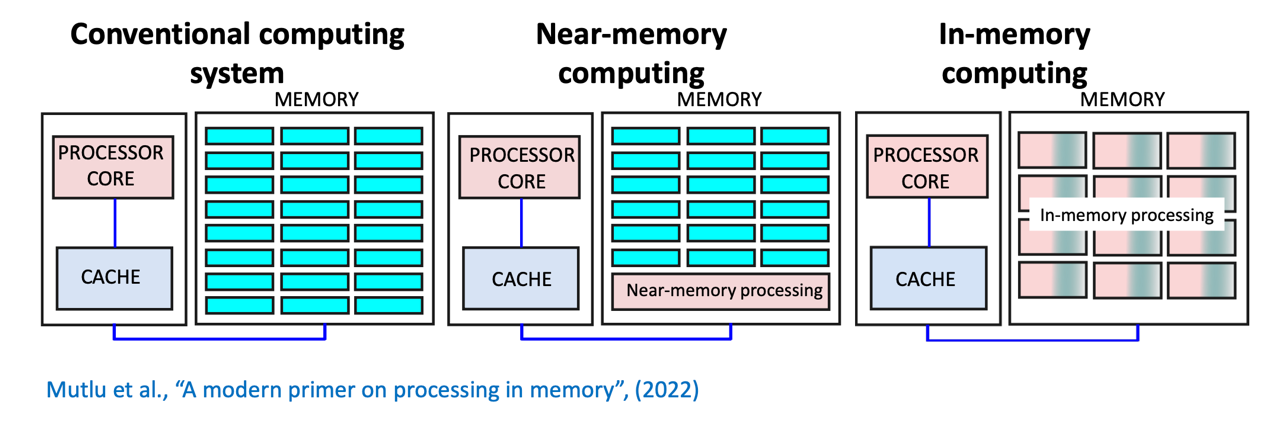


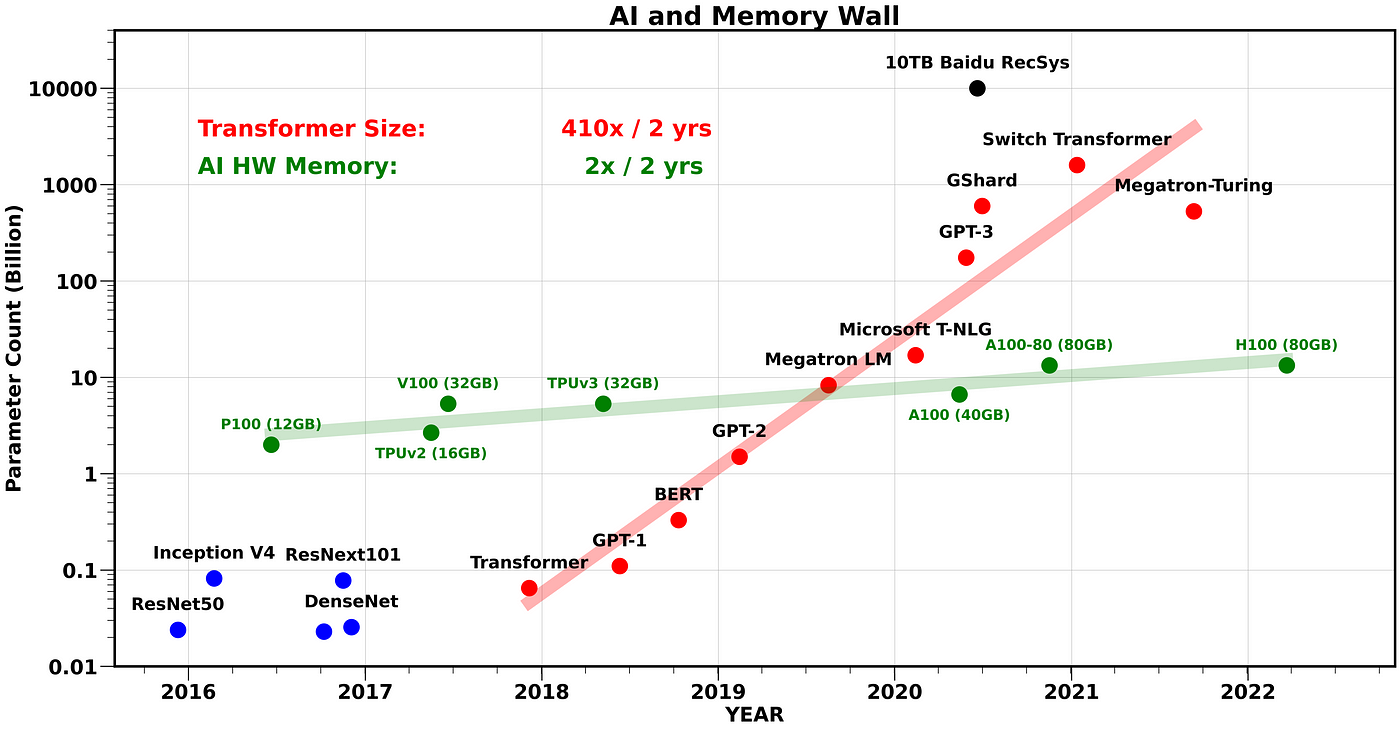
To deal with these massive models AI systems are designed into larger and larger clusters of CPUs and GPUs, sharing data and memory across the entire cluster.
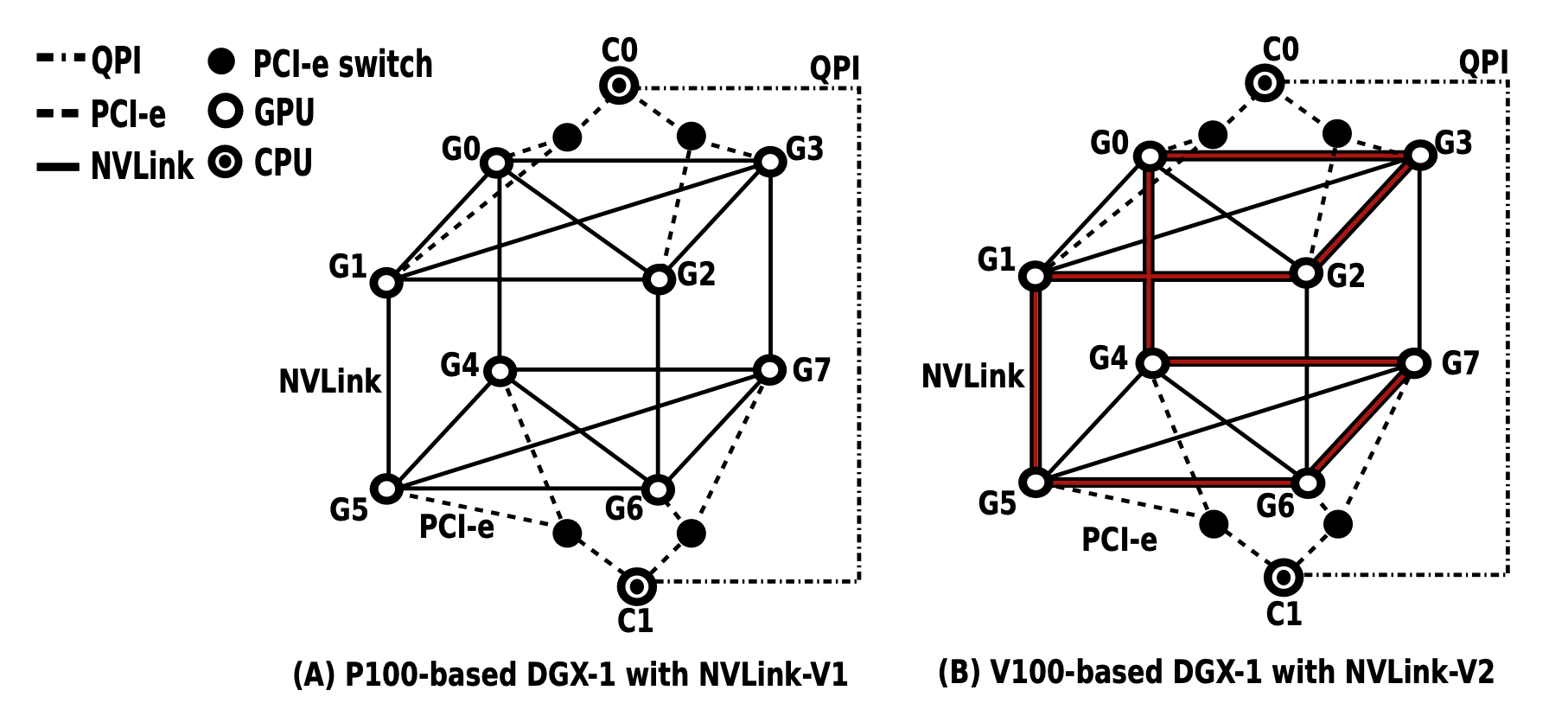
A. Li et al., “Evaluating Modern GPU Interconnect: PCIe, NVLink, NV-SLI, NVSwitch and GPUDirect,” in IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 1, pp. 94-110, 1 Jan. 2020
One of the unknowns of the AI space is what happens to these AI processing clusters when the number of processors gets into the tens or hundreds of thousands. What happens when the system faults and has to be rebooted? Do you have to go to remote memory storage to retrieve the billions of parameters? What is the cost in system downtime, loss of service, and limits to scaling? A persistent cache for SRAM backup and recovery that works as fast as SRAM and provides significant fault recovery advantages could be of significant benefit to AI system architects.
Also, as we have discussed there is a movement toward leveraging analog cells to both simplify and speed up the processing of these models. Today 70-80% of the processing requirements for AI is consumed by these weighted vector operations, so even minor improvements have the promise to deliver large gains. Much of the work in Analog In-Memory Compute is still in the research stage at leading universities and corporations but the interest is high in pursuing this as a potentially highly efficient architecture. The analog characteristics of 4DS’ cell lends itself to use in these emerging architectures. 4DS is open to starting these discussions with the industry’s most leading-edge players.
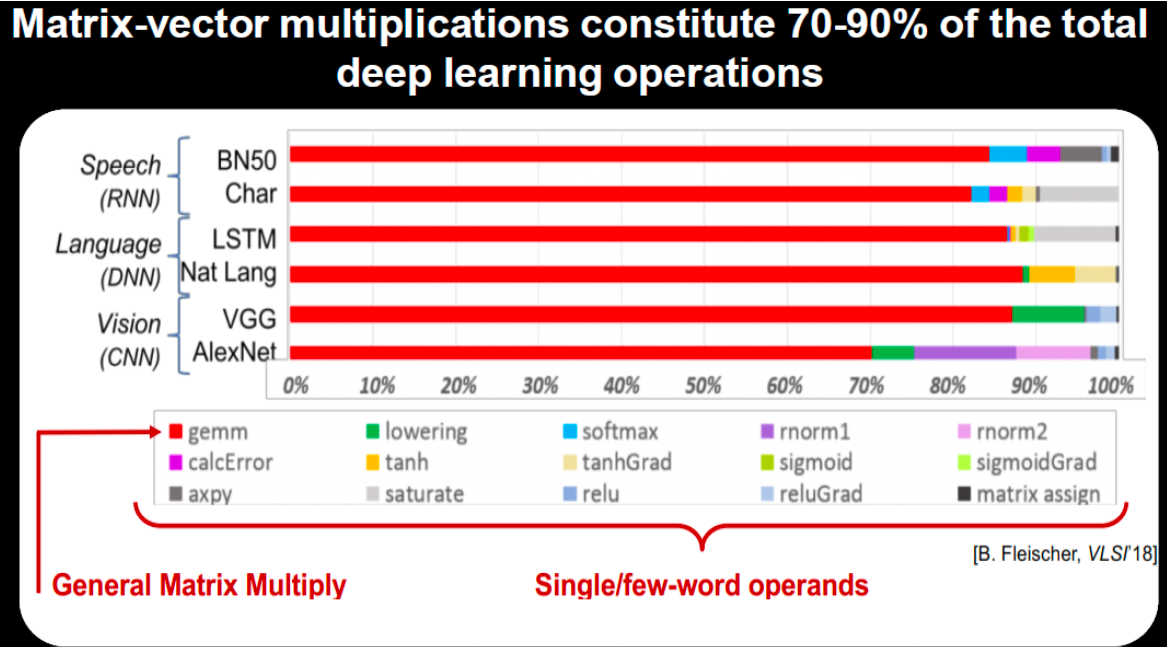
B. Fleischer and S. Shukla. (2018). Unlocking the Promise of Approximate Computing for on-Chip AI Acceleration.
Sign up for the latest news from 4DS Memory
Engage with us directly by asking questions, watching video summaries and seeing what other shareholders have to say via our investor hub.